SAN Extension
12.03 2024 | by massimilianoArchitettura di riferimento Per garantire continuità temporale all’erogazione dei servizi, si ricorre generalmente a soluzioni orientate alla realizzazione di una […]
Architettura di riferimento
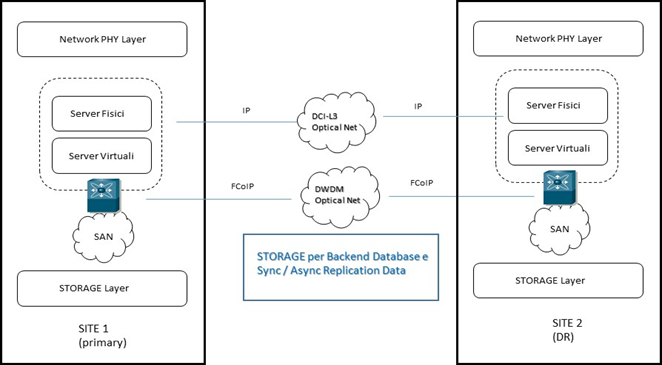
Per garantire continuità temporale all’erogazione dei servizi, si ricorre generalmente a soluzioni orientate alla realizzazione di una SAN (Storage Area Network) geograficamente distribuita.
In questa ottica, i sistemi di storage interoperano sfruttando un’infrastruttura di rete di trasporto dedicata. Le operazioni di data replication, necessarie a garantire un servizio di business continuity e disaster recovery, risultano dunque semplificate nel caso in cui i sistemi, seppur localizzati in aree differenti, siano tra loro interoperanti.
Le soluzioni che permettono la realizzazione di architetture di questo tipo vengono denominate “SAN Extension”.
La soluzione di SAN Extension permette sostanzialmente di eseguire su sistemi storage remoti tre differenti operazioni:
- data replication,
- accesso agli array di dischi da host remoti,
- condivisione di dati da parte di cluster distribuiti di server.
Una SAN Estesa può essere realizzata ricorrendo a diverse tecnologie. I fattori che ne condizionano la scelta sono generalmente tre e risultano tutti fortemente legati all’obiettivo di garantire operatività, efficienza e continuità temporale all’erogazione dei servizi applicativi:
- Recovery time objective (RTO)
- Recovery point objective (RPO)
RTO indica il tempo tollerabile da un’organizzazione che può intercorrere tra un evento disastroso e il ripristino dei servizi interessati.
RPO rappresenta il livello di aggiornamento dei dati ripristinati in seguito ad un evento disastroso. Esso risulta indicativo del quantitativo massimo di dati che un’organizzazione ha preventivamente accettato come essere sacrificabili in caso di fault.
La scelta dei sistemi, la definizione dei processi e l’adozione delle tecnologie per una soluzione di SAN extention, sono quindi fortemente legati alla rispondenza ai valori di RTO e RPO prefissati dall’azienda. Allo stesso tempo, sempre in ottica di disaster recovery, per approssimare il valore effettivo di RPO a zero risulta indispensabile analizzare le distanze che intercorrono tra i data center e la tolleranza delle applicazioni alla latenza introdotta dalla rete.
Le seguenti tecniche sono impiegate distintamente per l’ottimizzazione del valore effettivo di RPO offerto dal servizio di disaster recovery:
- Tape backup e restore;
- Periodic replication e backups;
- Asynchronous replication;
- Synchronous replication
Il “Disaster Radius” rappresenta il raggio di estensione dell’area geografica interessata da un ipotetico evento disastroso.
Esso viene valutato su base statistica in relazione alla conformazione fisica e alla stabilità politica della regione da cui vengono erogati i servizi e/o sono presenti le basi dati. La localizzazione dei data center e dei siti di disaster recovery viene valutata sulla base del calcolo del disaster radius.
Replication and Mirroring
Il data replication ed il mirroring hanno due obiettivi primari quali prendere i dati dal recovery site e ottimizzare al massimo il valore di RPO ed abilitare il rapid restoration.
Vi sono due metodi di Replication:
- Host-based mirroring
- Disk-based replication
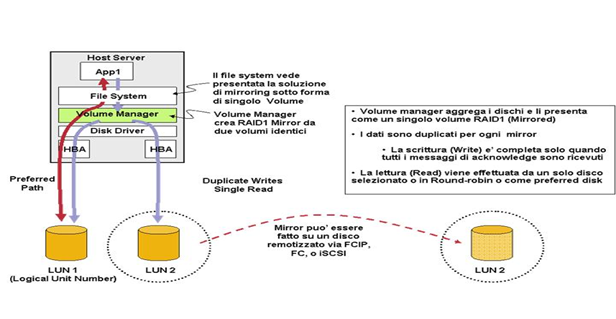
Il metodo di Host-Based mirroring si basa sul principio di replica sincrona dei dati su Logical Unit Number (LUN) differenti. Questo è possibile impiegando sui sistemi server un particolare driver intermedio, denominato “Volume Manager”, che maschera al file systems la batteria di dischi connessi presentandoli come un singolo “volume” o anche chiamato “Virtual Disk”.
In questo modo il Volume Manager che si interfaccia direttamente ai dischi fisici e prende in carico la gestione del loro indirizzamento, permette:
- la concatenazione di più dischi,
- RAID-0 (Striping),
- RAID-1 (Mirroring),
- RAID-5
Il diagramma seguente mostra l’operazione di Host-based Replication nel caso di una soluzione di mirroring RAID-1.
I dischi possono essere connessi localmente e direttamente al servente o remotizzati via Fiber Channel, Fiber Channel over IP o iSCSI.
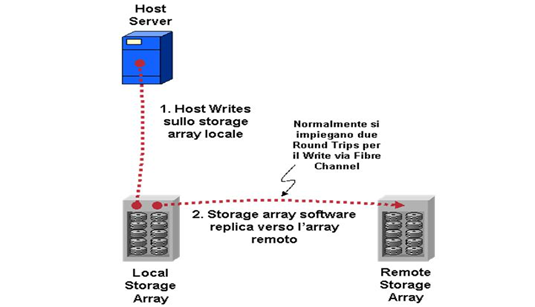
Il metodo Disk-based replication prevede un’architettura di storage array distribuita dotata di almeno due componenti fondamentali:
- array di dischi interconnessi in locale o in remoto,
- software per la gestione e il controllo dell’operazione di replication.
I server effettuano l’operazione di lettura e di scrittura in relazione all’array locale. L’operazione di replication è direttamente effettuata tra gli array secondo dei meccanismi sincroni o asincroni che cambiano da produttore a produttore:
- EMC: SRDF
- HDS: Truecopy
- HP: CA EVA
- IBM: PPRC
La replica dunque è trasparente per l’host e non introduce sullo stesso un overhead computazionale.
Synchronous Replication
La replica sincrona è una procedura di duplicazione dei dati in tempo reale da un sistema primario a un sito secondario. Essa prevede che i dati che vengono aggiornati sul server primario debbano essere duplicati sui siti secondari prima che si possa procedere con la transazione successiva, e questo assicura che i dati siano identici su tutti i sistemi di storage chiamati in causa.
L’obiettivo della replica sincrona è garantire, in caso di guasto, una perdita di dati praticamente nulla (RPO pari a 0) e un tempo di recovery (RTO) estremamente breve.
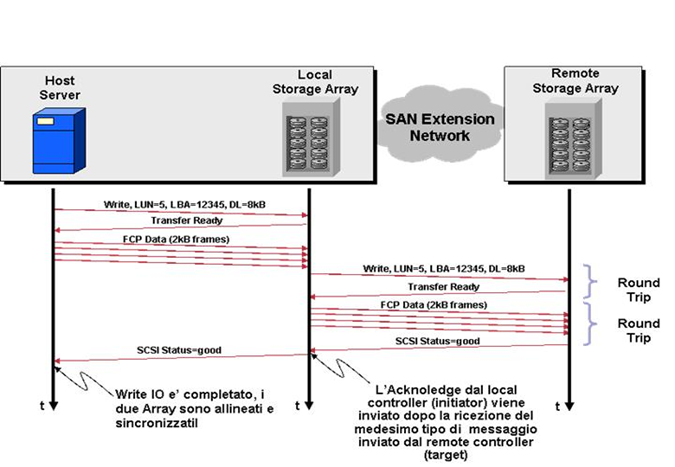
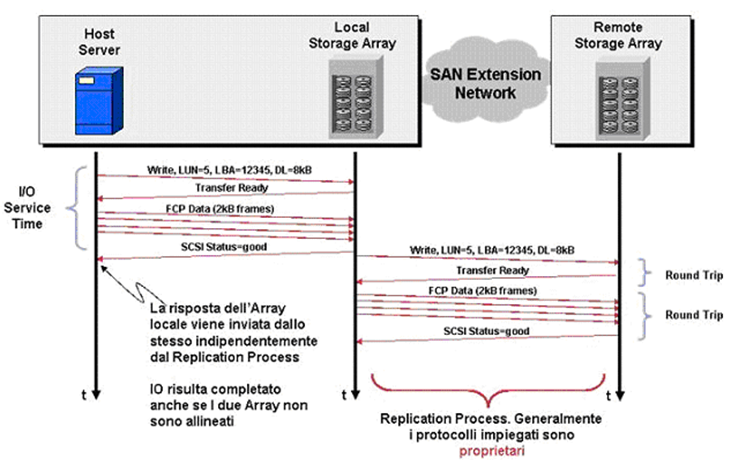
La figura seguente mostra come si sviluppa lo scambio di informazioni nel caso in cui il protocollo di comunicazione sia SCSI. Le fasi salienti della procedura sono:
- Command,
- Data Transfer,
- Status
L’host considera la procedura completata solo dopo aver ricevuto il messaggio di “Acknowledge” dal local array. L’operazione di “Replicated Write exchange” richiede due “Round Trip Time” tra i due storage arrays.
Questo intervallo di tempo è variabile a seconda della distanza tra i due siti e di conseguenza può risultare più o meno penalizzante per l’applicazione.
Asynchronous Replication
La replica asincrona presuppone un disaccoppiamento temporale tra l’operazione di scrittura dei dati sull’array locale e la loro duplicazione sull’array remoto. Il processo di replica può avvenire automaticamente ogni qualvolta avviene un aggiornamento, o a intervalli di tempo predefiniti.
È anche possibile mettere i dati in attesa per poi spedirli a blocchi quando il traffico di rete è più ridotto.
La replica asincrona quindi non impegna le risorse trasmissive alla stregua di quella sincrona e può essere impiegata indipendentemente dalle distanze in gioco.
Un esempio di implementazione asincrona è quello visualizzato in figura seguente:
Network Latency
La rete di trasporto che permette a sistemi distribuiti di storage array di interoperare, introduce una latenza, il cui valore cambia in relazione alla distanza e alla tecnologia trasmissiva impiegata.
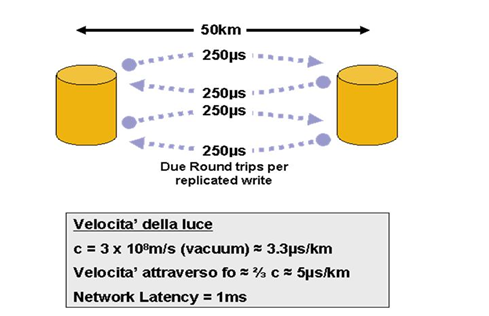
Nel caso di reti ottiche si considera una latenza, introdotta dalla propagazione del segnale luminoso su fibra ottica, pari a circa 5µs per Km.
Il Round Trip Time risulta quindi di 10µs per km e il ritardo totale sull’operazione di scrittura pari a 20µs.
La figura seguente mostra il caso di una distanza tra due siti di 50 Km. L’effetto sull’applicazione dovuto alla replica sincrona dei dati e’ quello di un ritardo totale di 1 ms.
Il degrado subito dall’applicazione all’aumentare delle distanze diviene ad un certo punto tale da non risultare più consigliabile una tecnica di replica sincrona dei dati.